Accomplishments
Contributions Summary Table
HPC Colony Contributions Summary | |
| Publications | 40 |
| Invited Talks | 27 |
| Software Products | 2 |
| Ph.D. Candidates at Univ. of Illinois | 2 |
| Summer Interns at ORNL | 2 |
Allocation Awards
HPC Colony Allocation Awards | |
| ORNL Director's Discretion | We are grateful to ORNL's Director Discretion program ( http://www.nccs.gov/user-support/access/project-request/) for all of their help, assistance, and machine access. |
| ERCAP | We are grateful to the NERSC ERCAP program (http://www.nersc.gov/users/accounts/allocations/overview/) for providing access to leadership-class resources for 2011 and 2012. |
| INCITE | We are grateful to the DOE INCITE program ( http://science.energy.gov/ascr/facilities/incite/) for providing access to leadership-class resources for 2010. |
| BGW Day | We are grateful to the Blue Gene Consortium and IBM for offering us time on BGW and for giving us the opportunity to test our codes on the full system. In particular, we thank Fred Mintzer and his team at IBM for the support provided during BGW-Day. |
Performance/Scaling Results
| HPC Colony Performance/Scaling Measurements (citations available here) | ||
| Charm Adaptive Load Balancing | 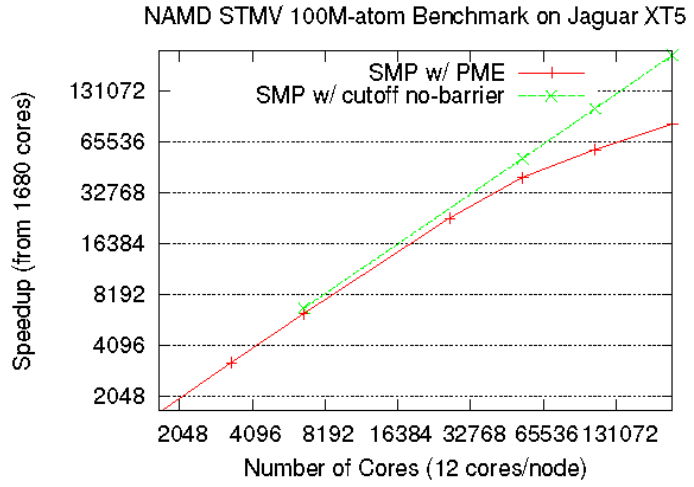 |
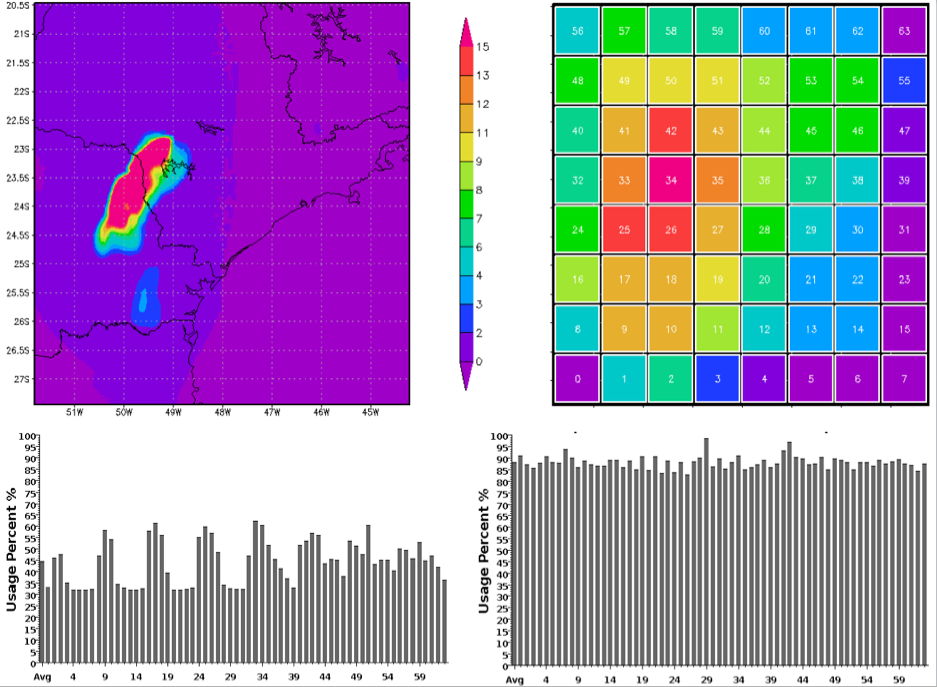 |
| Figure 1: Scaling of NAMD on ORNL's Jaguar under different configurations. The results show excellent scaling derived from our hierarchical load-balancer for a 100 million atom test on Jaguar running on 224,000 cores. | Figure 2: Measurements obtained from the BRAMS weather forecasting model. The top 2 figures demonstrate that more load is present in zones experiencing storms, and the bottom two figures illustrate how our load-balancing algorithms are able to redistribute the work for improved performance. | |
| Charm Improved Checkpoint/Restart | 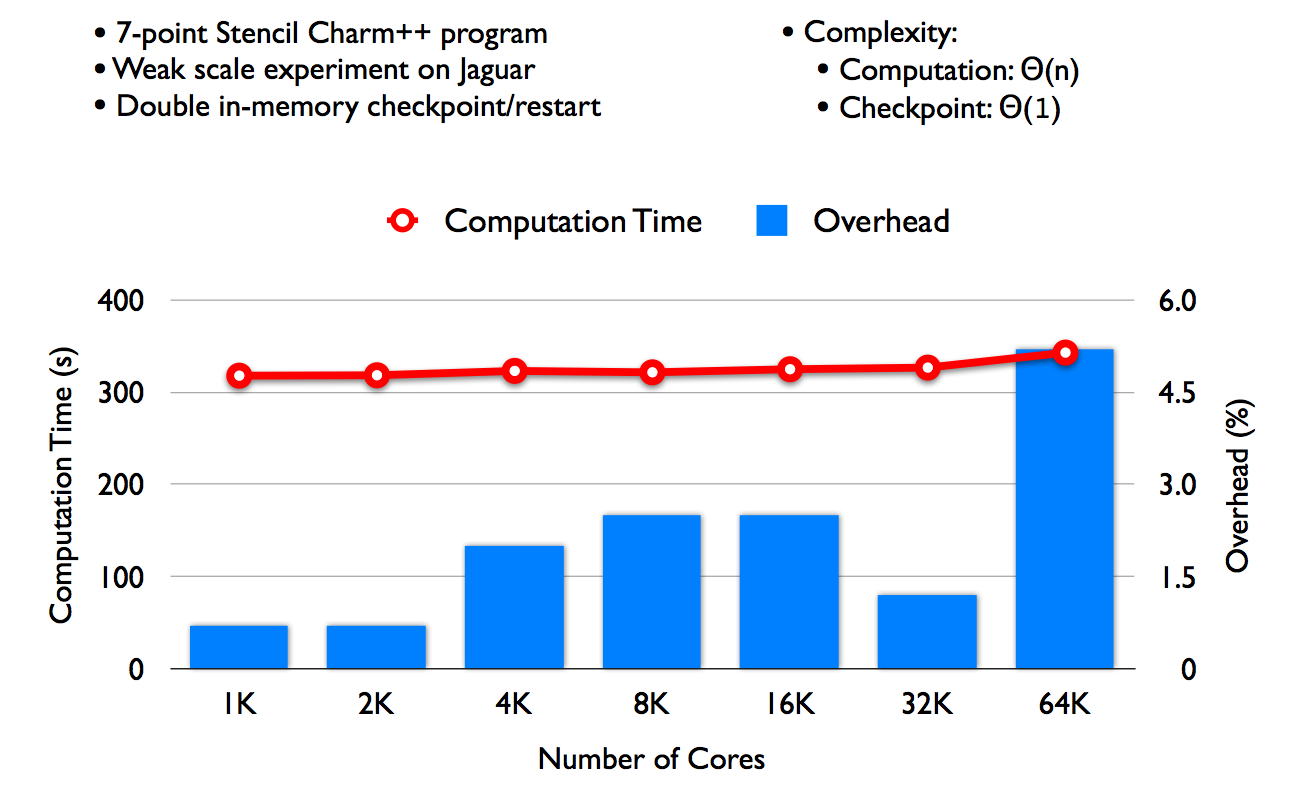 |
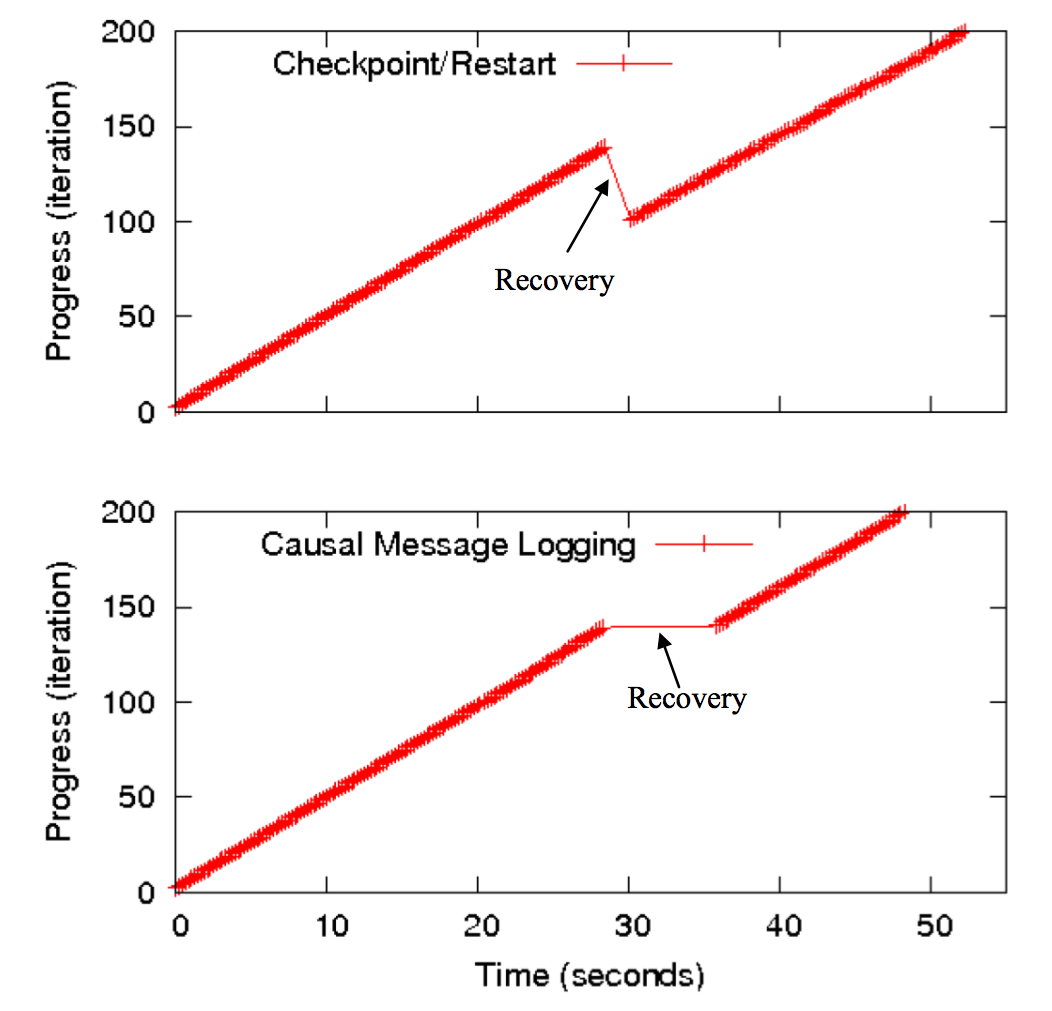 |
| Figure 3: Scaling of Charm's In-Memory checkpoint-restart scheme in forward direction (overhead in the event of no failure). Using O(n) algorithms for computation and O(1) algorithms for communication, the scheme is able to scale to 64K with under 6% overhead. | Figure 4: Causal message logging performance in the face of a failure. The figure plots the application progress, in terms of completed iterations, as a function of elapsed time. In the checkpoint-restart case, the work of a few iterations (i.e. 100 to 140) needs to be redone when the failure occurs; meanwhile, with causal message-logging, only the failing processor requires its work to be repeated, and other processors that do not depend on it can proceed. | |
| Coordinated Scheduling Kernel | 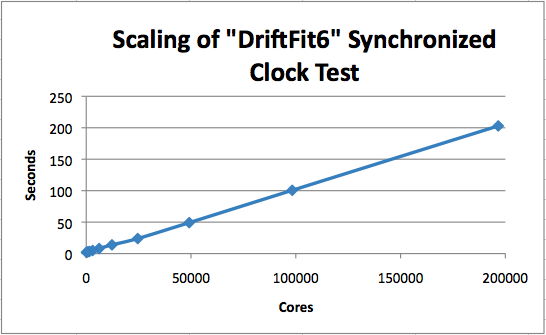 |
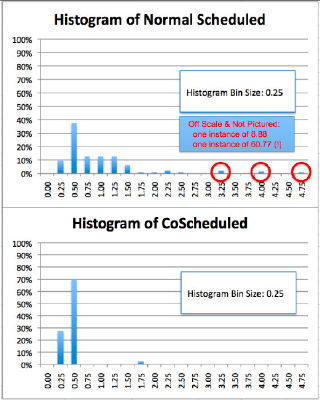 |
| Figure 5: Measurements obtained from Colony's synchronized clock algorithm exhibit excellent scaling characteristics. | Figure 6: Coordinated and uncoordinated schedulings. The above figure portrays a histogram of runs with and without coordinated scheduling. The lower histogram includes coordinated scheduling which results in much lower variability of synchronizing collective operations. |
|
| SpiderCAST communications infrastructure | 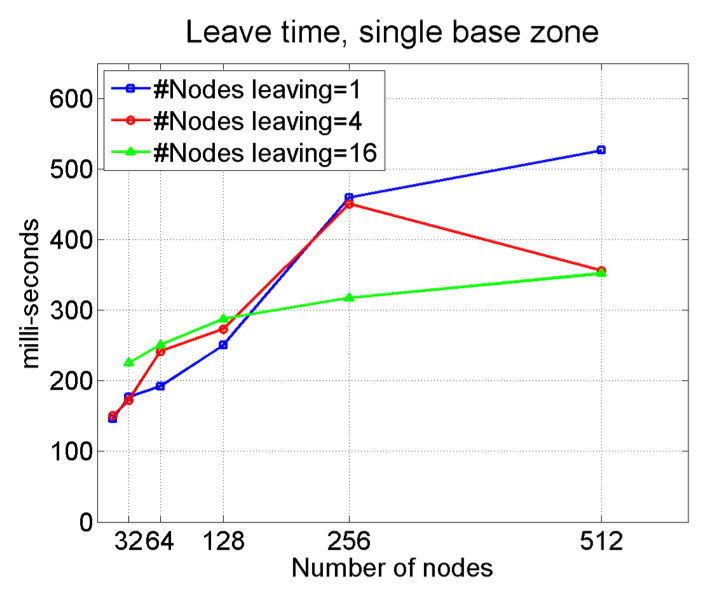 |
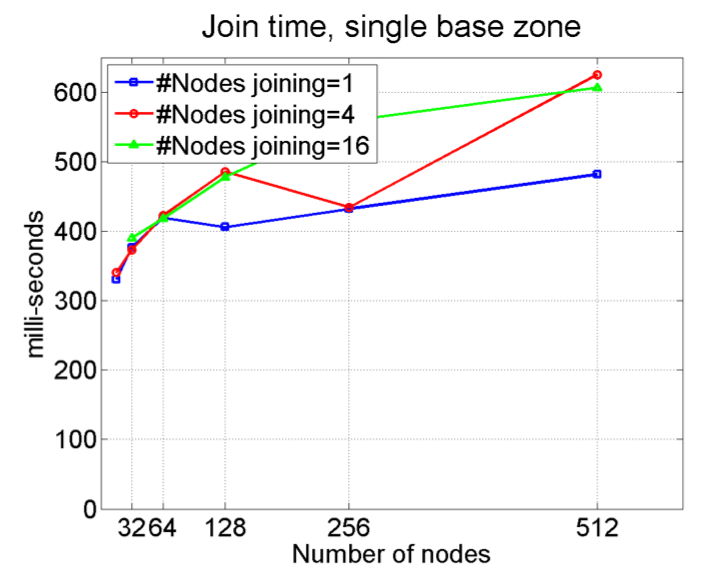 |
| Figure 7: We measure the time for join-events to propagate through the overlay, on different view sizes and different number of nodes joining. Results indicate that a 512-node zone propagates 16 concurrent joins to every member at TJoin(512,16)~0.6s; Moreover the number of nodes joining concurrently has a very small effect on the latency. | Figure 8: Similarly, we measure the time for leave-events to propagate through the overlay, on different view sizes and different number of nodes leaving. Results indicate that a 512-node zone propagates 16 concurrent leaves to every member at TLeave(512,1)~0.35s; As with the case of joining, the number of nodes leaving concurrently has a very small effect on the latency. | |